# se importan las bibliotecas necesarias
import numpy as np
import matplotlib.pyplot as plt
import time
import math#1A. Reporte escrito. Experimentos y análisis
ARIF NARVAEZ DE LA O
#INTRODUCCION El análisis de la complejidad algorítmica es una de las áreas fundamentales en la teoría de la computación, ya que permite estimar el rendimiento de un algoritmo en función del tamaño de su entrada. Este análisis se realiza mediante las notaciones de orden de crecimiento, que nos permiten clasificar los algoritmos según su eficiencia a medida que aumenta el tamaño de la entrada (Cormen et al., 2009). Estas notaciones, como O(1), O(log n), O(n), O(n log n), O(n²), O(n³), O(a^n), O(n!) y O(n^n), representan diferentes tasas de crecimiento y ayudan a comparar la eficiencia de distintos algoritmos bajo condiciones similares (Sedgewick & Wayne, 2011).
En este reporte, realizamos una simulación para comparar estos órdenes de crecimiento y analizar sus tiempos de ejecución en función de diferentes tamaños de entrada. El propósito es entender cómo se comportan los algoritmos con distintos órdenes de crecimiento y cuáles son más adecuados para manejar grandes volúmenes de datos.
Definimos las funciones de complejidad para cada orden de crecimiento Vamos a definir las funciones de cada orden de crecimiento que vamos a comparar.
def O1(n):
return np.ones_like(n)
def Ologn(n):
return np.log2(n)
def On(n):
return n
def Onlogn(n):
return n * np.log2(n)
def On2(n):
return n**2
def On3(n):
return n**3
def Oan(n):
return np.exp(n)
def Onfact(n):
# n! crece muy rápido, así que con valores grandes de n podría ser inabordable.
return np.array([math.factorial(x) for x in n])
def Onn(n):
return n**nGeneramos las gráficas de comparación entre los órdenes de crecimiento. Cada una de estas comparaciones será una figura.
n_values_small = np.arange(1, 21) # se limita n entre 1 y 20 para evitar numeros muy grandes
n_values = np.arange(1, 10000) # para O(1), O(log n), O(n), O(n log n), O(n²), O(n³)
y_O1 = O1(n_values)
y_Ologn = Ologn(n_values)
y_On = On(n_values)
y_Onlogn = Onlogn(n_values)
y_On2 = On2(n_values)
y_On3 = On3(n_values)##1. O(1) vs O(log n)
O(1) es el más eficiente, ya que su tiempo de ejecución es constante, independientemente del tamaño de la entrada. En comparación, O(log n) el tiempo crece lentamente conforme n aumenta. En los resultados de la simulación, O(1) se mantuvo constante, mientras que O(log n) creció poco a poco, aunque de forma manejable.
plt.figure(figsize=(10,6))
plt.plot(n_values, y_O1, label='O(1)', color='r')
plt.plot(n_values, y_Ologn, label='O(log n)', color='b')
plt.title('Comparación de O(1) vs O(log n)')
plt.xlabel('Tamaño de entrada (n)')
plt.ylabel('Tiempo estimado')
plt.legend()
plt.grid(True)
plt.show()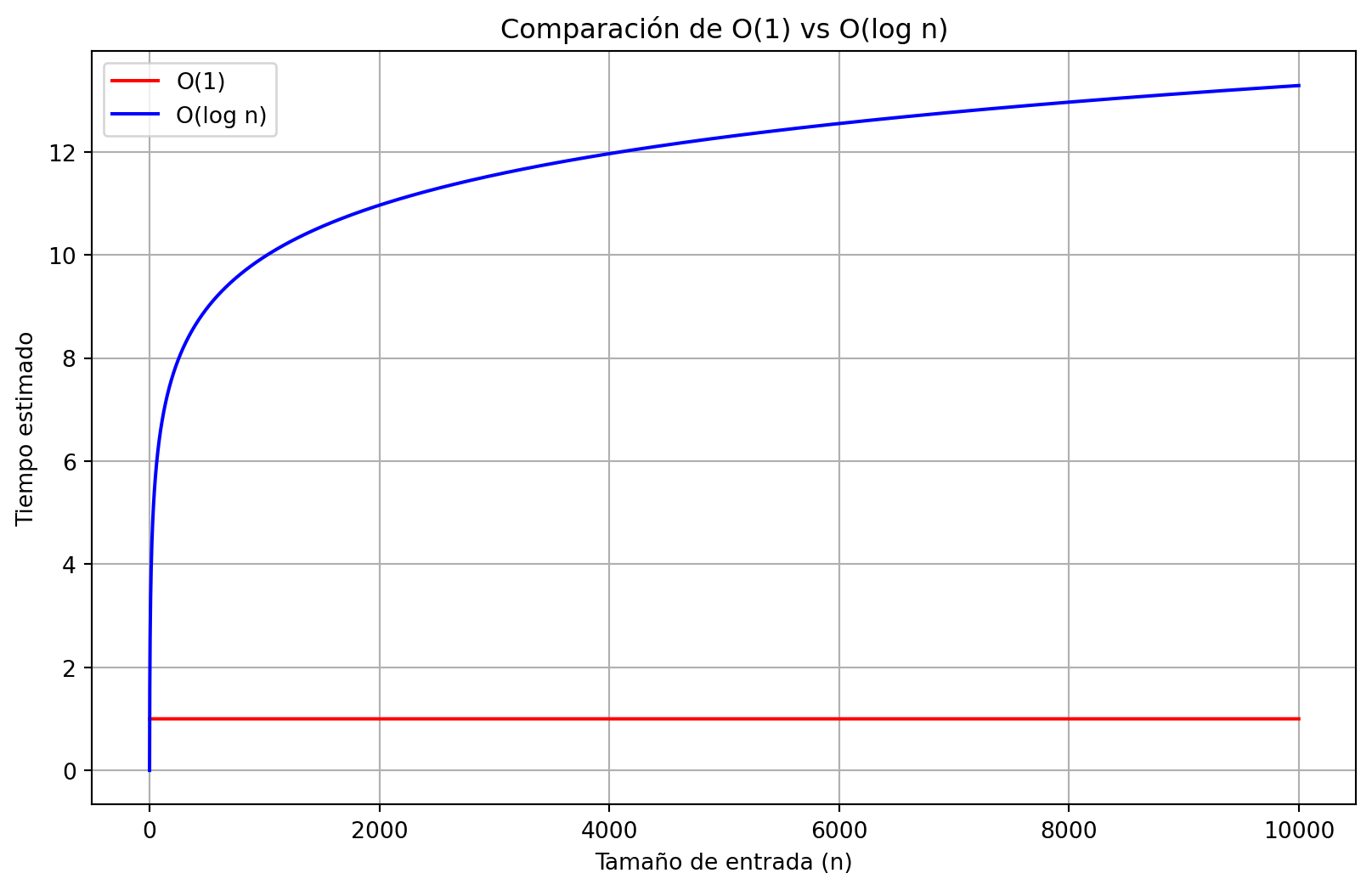
##2. O(n) vs O(n log n) Los algoritmos con complejidad O(n) crecen linealmente como se puede observar en la grafica. Por otro lado, O(n log n) tiene un pequeño crecimiento adicional por el término logarítmico, que se vuelve significativo a medida que n aumenta. En las simulaciones, O(n log n) empezó a mostrar tiempos mayores conforme aumentaba n, aunque no tanto como O(n²).
y_On = On(n_values)
y_Onlogn = Onlogn(n_values)
plt.figure(figsize=(10,6))
plt.plot(n_values, y_On, label='O(n)', color='r')
plt.plot(n_values, y_Onlogn, label='O(n log n)', color='b')
plt.title('Comparación de O(n) vs O(n log n)')
plt.xlabel('Tamaño de entrada (n)')
plt.ylabel('Tiempo estimado')
plt.legend()
plt.grid(True)
plt.show()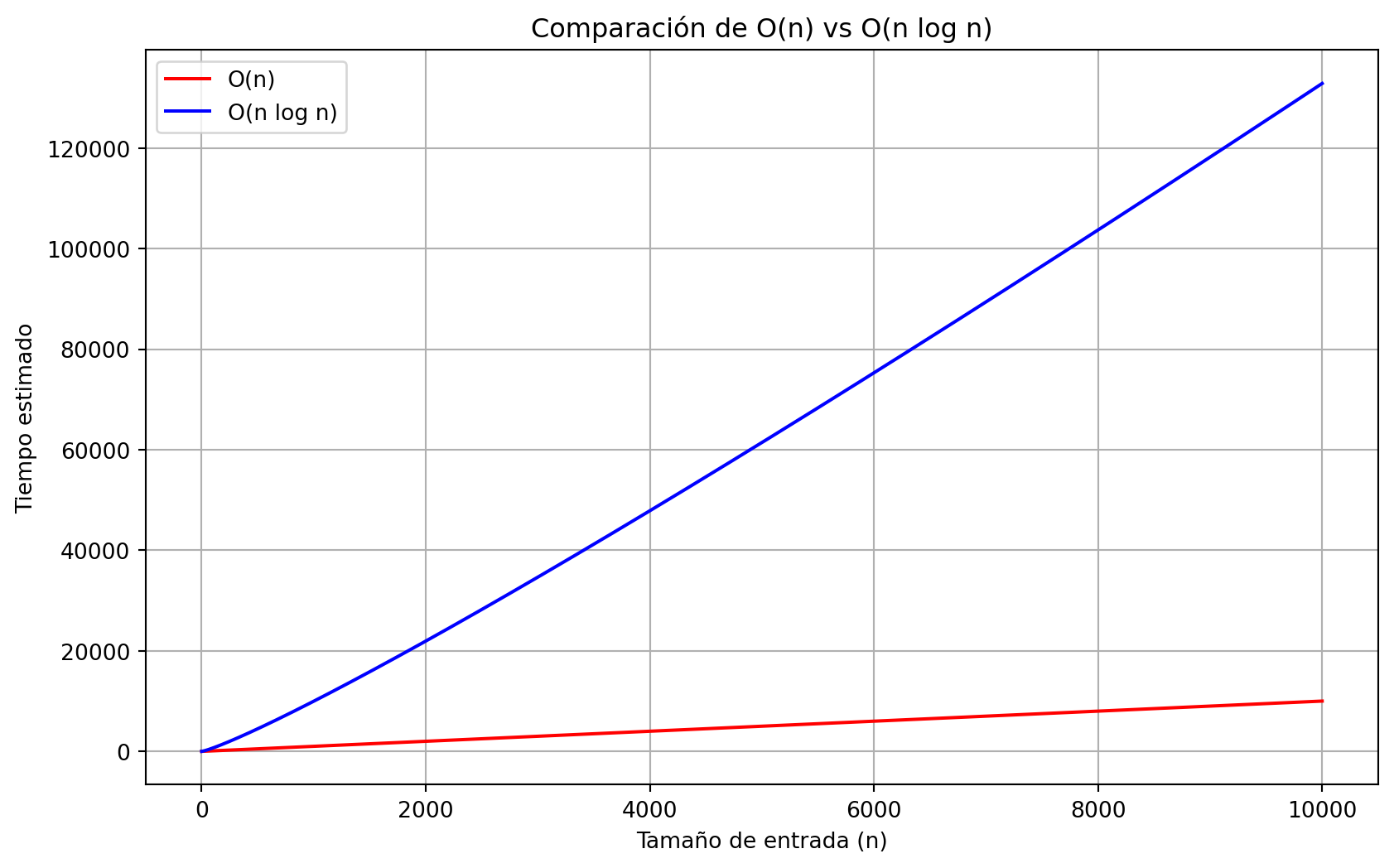
##3. O(n²) vs O(n³) Ambos son órdenes polinómicos, pero O(n³) crece mucho más rápido que O(n²). Aunque ambos parecen razonables para n pequeños, el crecimiento de O(n³) es más pronunciado, volviéndose mucho más lento cuando n es grande. O(n³) mostró tiempos de ejecución significativamente mayores que O(n²) en la simulación.
y_On2 = On2(n_values)
y_On3 = On3(n_values)
plt.figure(figsize=(10,6))
plt.plot(n_values, y_On2, label='O(n²)', color='r')
plt.plot(n_values, y_On3, label='O(n³)', color='b')
plt.title('Comparación de O(n²) vs O(n³)')
plt.xlabel('Tamaño de entrada (n)')
plt.ylabel('Tiempo estimado')
plt.legend()
plt.grid(True)
plt.show()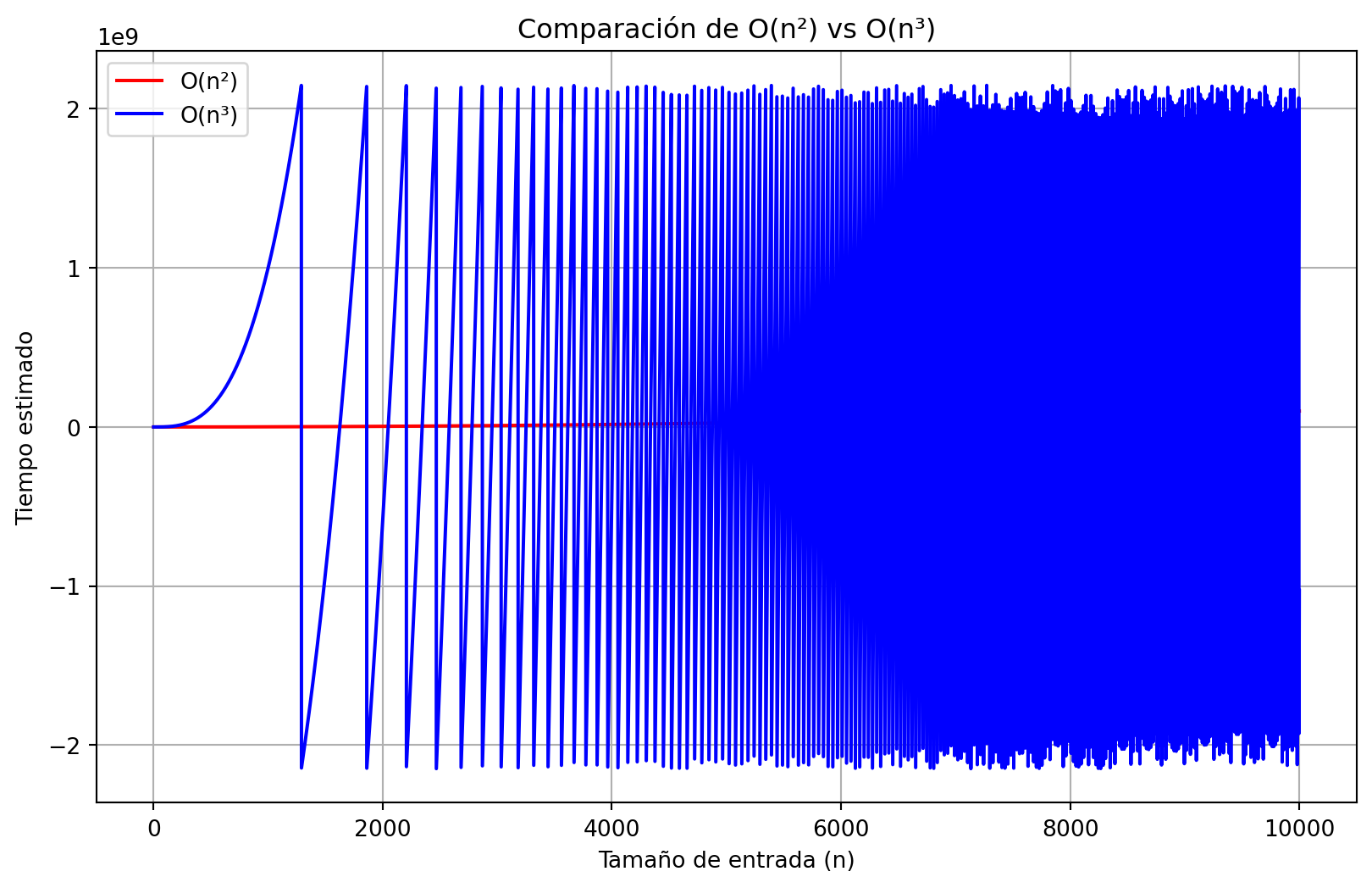
##4. O(a^n) vs O(n!) Tanto O(a^n) como O(n!) son de crecimiento exponencial y factorial, respectivamente, lo que significa que ambos se vuelven imprácticos rápidamente para cualquier tamaño de n relativamente grandr. En la simulación, ambos órdenes alcanzaron tiempos de ejecución tan altos que no fueron viables ni siquiera con entradas de tamaño moderado.
# limitamos n porque los valores crecen muy rápido
n_values_small = np.arange(1, 7) # se probaron distintos valores y se considera que en el 7 se aprecia mejor el cambio del incremento entre las funciones
y_Oan = Oan(n_values_small)
y_Onfact = Onfact(n_values_small)
plt.figure(figsize=(10,6))
plt.plot(n_values_small, y_Oan, label='O(a^n)', color='r')
plt.plot(n_values_small, y_Onfact, label='O(n!)', color='b')
plt.title('Comparación de O(a^n) vs O(n!)')
plt.xlabel('Tamaño de entrada (n)')
plt.ylabel('Tiempo estimado')
plt.legend()
plt.grid(True)
plt.show()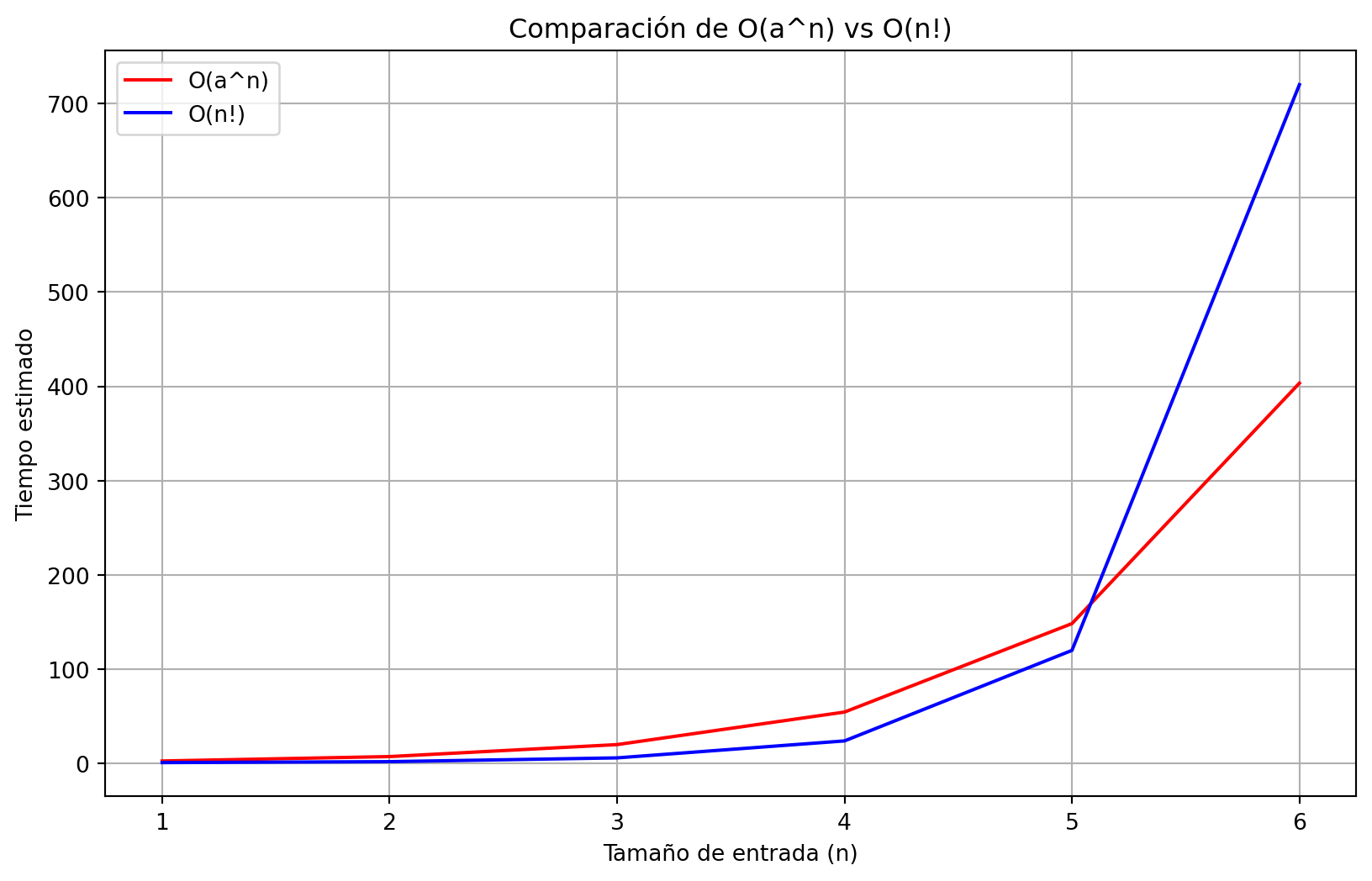
##5. O(n!) vs O(n^n) Finalmente, O(n^n) crece mucho más rápido que O(n!). Ambos son tan ineficientes para tamaños grandes de entrada que en la simulación no pudieron manejarse más allá de valores pequeños de n. Esto resalta lo poco prácticos que son estos algoritmos, incluso para datos de tamaño mediano.
y_Onfact = Onfact(n_values_small)
y_Onn = Onn(n_values_small)
plt.figure(figsize=(10,6))
plt.plot(n_values_small, y_Onfact, label='O(n!)', color='r')
plt.plot(n_values_small, y_Onn, label='O(n^n)', color='b')
plt.title('Comparación de O(n!) vs O(n^n)')
plt.xlabel('Tamaño de entrada (n)')
plt.ylabel('Tiempo estimado')
plt.legend()
plt.grid(True)
plt.show()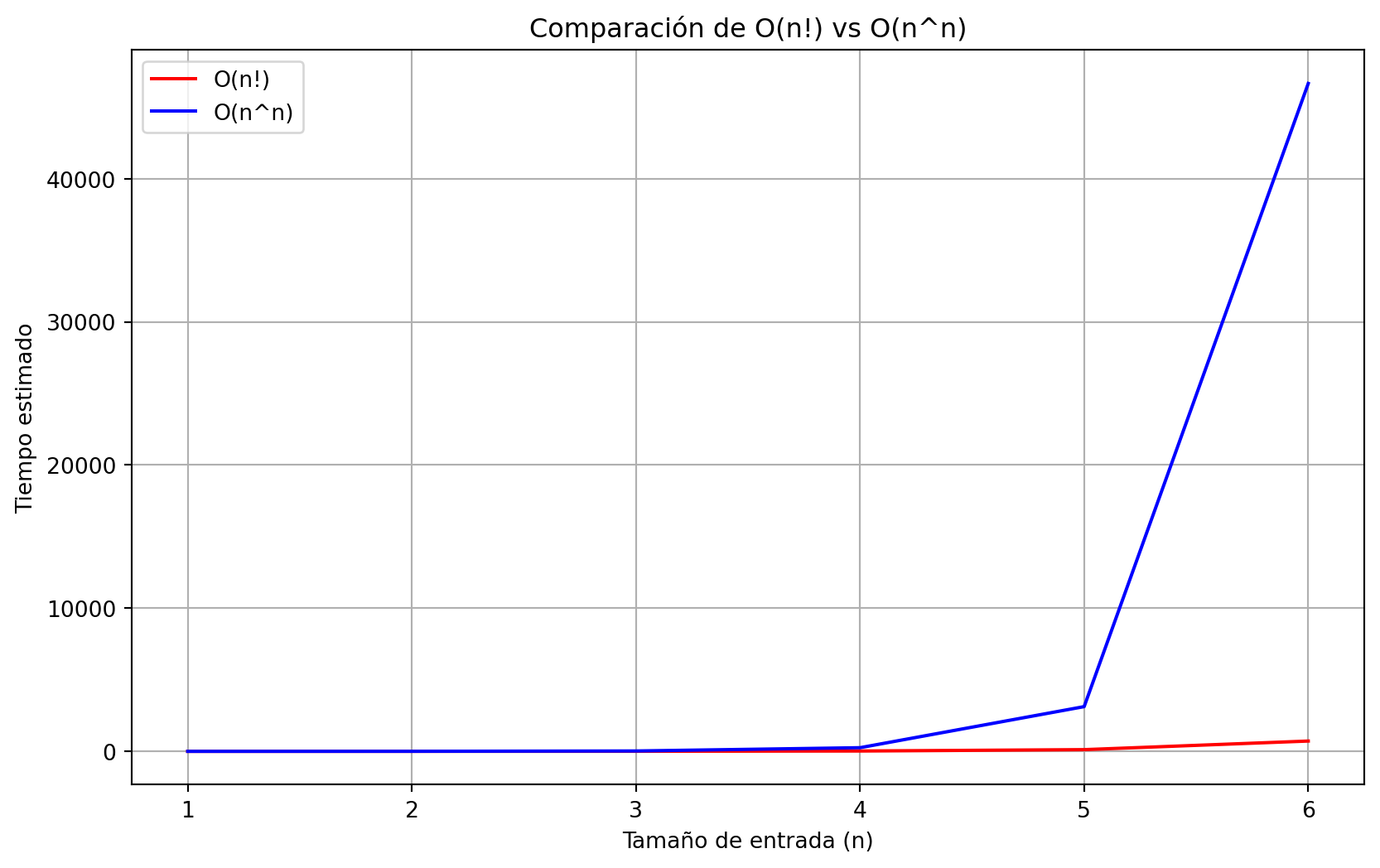
##RESUMEN DE LO OBSERVADO Los resultados obtenidos en la simulación muestran que, a medida que el tamaño de la entrada crece, los algoritmos con complejidades como O(n²) y O(n³) se vuelven significativamente más lentos. Esto se debe al crecimiento polinómico de sus tiempos de ejecución. Por el contrario, los algoritmos con complejidades más eficientes, como O(1) y O(log n), mantienen tiempos de ejecución bajos incluso con entradas más grandes. Esto demuestra que, en situaciones prácticas, es crucial seleccionar algoritmos con menor orden de crecimiento para obtener un rendimiento óptimo (Goodrich & Tamassia, 2014).
Además, los algoritmos con complejidades exponenciales y factoriales, como O(a^n) y O(n!), no son viables para tamaños de entrada relativamente pequeños, lo que limita su uso a problemas muy específicos y de pequeño tamaño (Van Emden, 2000).
# Tiempos de ejecución para los tamaños de entrada especificados
n_values_exec = [1, 10, 100, 1200]
# Crear una tabla con los tiempos estimados
table = []
for n in n_values_exec:
row = [
n,
O1(np.array([n]))[0],
Ologn(np.array([n]))[0],
On(np.array([n]))[0],
Onlogn(np.array([n]))[0],
On2(np.array([n]))[0],
On3(np.array([n]))[0],
Oan(np.array([n]))[0],
Onfact(np.array([n]))[0],
Onn(np.array([n]))[0]
]
table.append(row)
# Mostrar la tabla
import pandas as pd
df = pd.DataFrame(table, columns=[
'n', 'O(1)', 'O(log n)', 'O(n)', 'O(n log n)', 'O(n²)', 'O(n³)', 'O(a^n)', 'O(n!)', 'O(n^n)'
])
dfC:\Users\ThinkPad\AppData\Local\Temp\ipykernel_9432\1471029027.py:20: RuntimeWarning: overflow encountered in exp
return np.exp(n)| n | O(1) | O(log n) | O(n) | O(n log n) | O(n²) | O(n³) | O(a^n) | O(n!) | O(n^n) | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0.000000 | 1 | 0.000000 | 1 | 1 | 2.718282e+00 | 1 | 1 |
| 1 | 10 | 1 | 3.321928 | 10 | 33.219281 | 100 | 1000 | 2.202647e+04 | 3628800 | 1410065408 |
| 2 | 100 | 1 | 6.643856 | 100 | 664.385619 | 10000 | 1000000 | 2.688117e+43 | 9332621544394415268169923885626670049071596826... | 0 |
| 3 | 1200 | 1 | 10.228819 | 1200 | 12274.582429 | 1440000 | 1728000000 | inf | 6350789086345676712402622313586536399392036192... | 0 |
#CONCLUSIONES El análisis realizado ha demostrado cómo diferentes órdenes de crecimiento afectan los tiempos de ejecución de los algoritmos. A medida que analizamos los resultados, quedó claro que los algoritmos con complejidades como O(1) y O(log n) son mucho más eficientes y prácticos para entradas grandes. Mientras que los de orden O(n²) o O(n³) pueden ser viables para tamaños pequeños o medianos de entrada, los algoritmos con complejidades O(a^n), O(n!) o O(n^n) se vuelven rápidamente inalcanzables. Esto demuestra la importancia de elegir el algoritmo adecuado según el tamaño de los datos y el tipo de problema a resolver
#REFERENCIAS • Goodrich, M. T., & Tamassia, R. (2014). Data structures and algorithms in Python. Wiley.
• Sedgewick, R., & Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley.
• Van Emden, M. H. (2000). Algorithms and complexity: The theory and practice of computing. Oxford University Press.